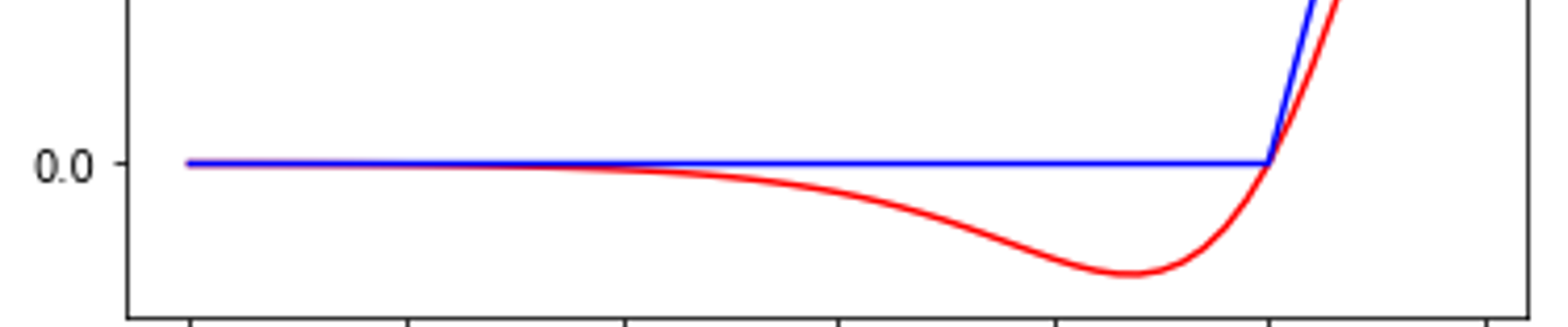
With ReLU, half of the values of the input are set to 0 after applying the activation function. With a derivative = 0, the weight is not updated, and if the weight is already 0 that results in Dead neurons.
Leaky Relu and Selu (self-normalizing Neural Networks) are potential alternatives but they do not perform very well.
Swish out-performs Relu for deep NN (more than 40 layers). Although, the performance or relu and swish model degrades with increasing batch size, swish performs better than relu.
1. SWISH activation function
- Defining the swish activation function in Tensorflow:
1
2
def swish(x):
return x * tf.nn.sigmoid(x)
2. b-SWISH activation function
where is a learnable parameter.
- Defining the b-swish activation function in Tensorflow:
1
2
3
def alt_swish(x):
beta = tf.Variable(initial_value=1.0, trainable=True, name='swish-beta')
return x * tf.nn.sigmoid(beta*x)