Cross-entropy for 2 classes:
Cross entropy for classes:
In this post, we derive the gradient of the Cross-Entropy loss with respect to the weight linking the last hidden layer to the output layer. Unlike for the Cross-Entropy Loss, there are quite a few posts that work out the derivation of the gradient of the L2 loss (the root mean square error).
When using a Neural Network to perform classification tasks with multiple classes, the Softmax function is typically used to determine the probability distribution, and the Cross-Entropy to evaluate the performance of the model. Then, with the back-propagation algorithm computed from the gradient values of the loss with respect to the fitting parameters (the weights and bias), we can find the optimum parameters that reduces to a minimum the loss between the prediction of the model and the ground truth. For example, the rule update to optimize the weight parameter is:
Let’s start by rolling out a few definitions:
-
Ground truth is a hot-encoded vector: where is the number of classes (number of rows).
-
Modeled/Predicted probability distribution: , where the -th element is given by the softmax transfer function.
-
Softmax transfer function: \begin{equation} \hat{y}_i = \frac{e^{z_i}}{\sum_k e^{z_k}} \end{equation} where is the -th pre-activation unit. The softmax transfer function is typically used to compute the estimated probability distribution in classification tasks involving multiple classes.
-
The Cross-Entropy loss (for a single example):
Simple model
Let’s consider the simple model sketched below, where the last hidden layer is made of 3 hidden units, and there are only 2 nodes at the output layer. We want to derive the expression of the gradient of the loss with respect to : .
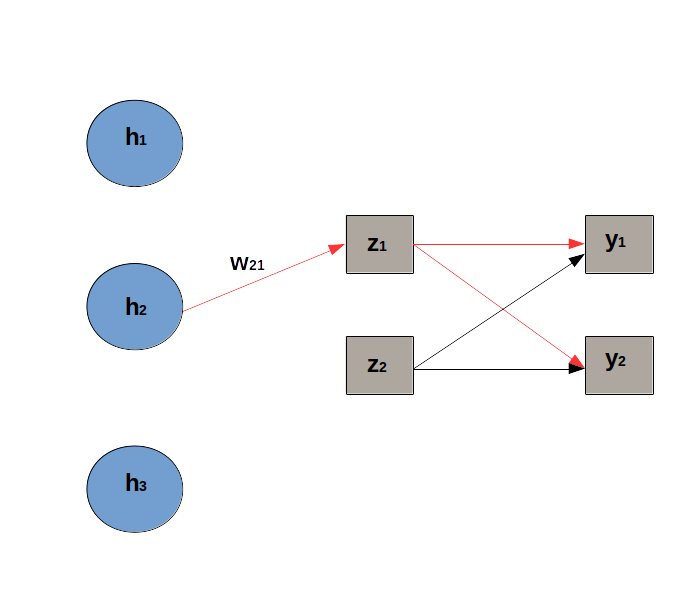
The 2 paths, drawned in red, are linked to .
The network’s architecture includes:
-
a last hidden layer with 3 hidden units.
-
The output layer has 2 units to predict the probability distribution with 2 classes.
-
is the weight linking unit to the pre-activation .
-
The pre-activation is given by:
Because, there are 2 paths through that leads to , we need to sum up the derivatives that go through each path:
Let’s calculate the different parts of the equation above:
1.
The pre-activation is given by: , hence:
2.
From the definition of the softmax function, we have , so:
We use the following properties of the derivative: and .
We can then simplify the derivative:
because .
3.
Again, from using the definition of the softmax function:
4.
We start with the definition of the cross-entropy loss: :
and similarly:
We can now put everything together:
Hence, finally:
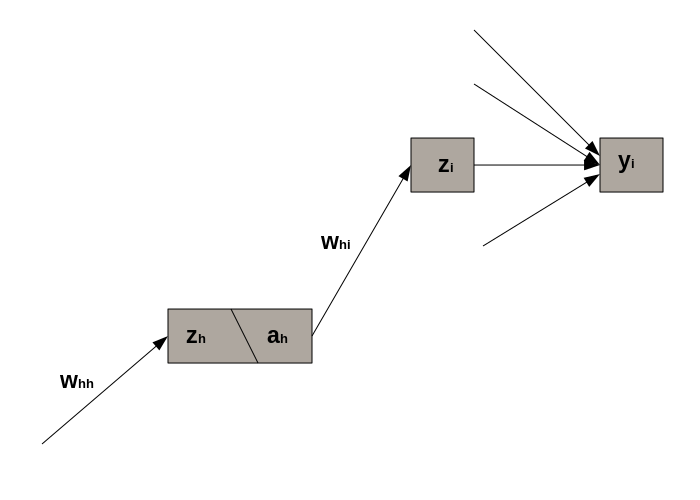
General form of
We start with the definition of the loss function: .
From the definition of the pre-activation unit , we get:
where is the activation of the -th hidden unit.
Now, let’s calculate . This term is a bit more tricky to compute because does not only contribute to but to all because of the normalizing term in .
Similarly to the toy model discussed earlier, we need to accumulate the gradients wrt from all relevant paths.
The gradient of the loss with respect to the output is:
Hence:
The next step is to calculate the other partial derivative terms:
Let’s replace the results above:
Finally, we get the gradient wrt