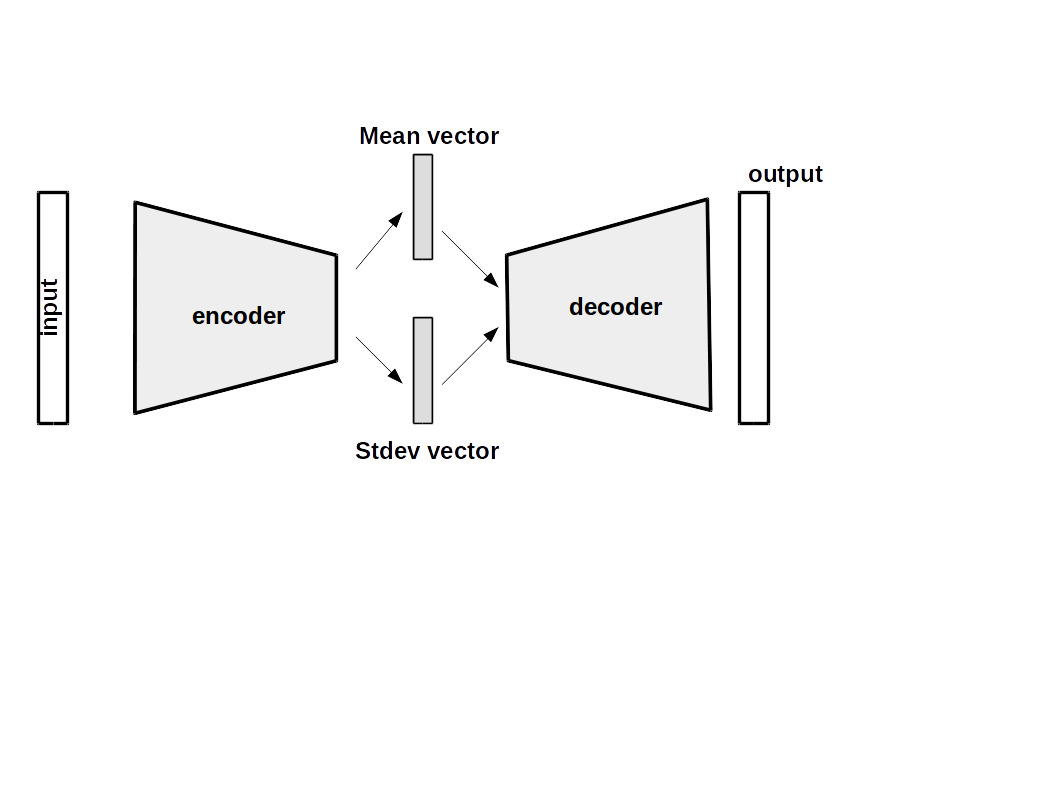
In autoencoder, we encode latent vectors from images that can only memorize images. It is not a generative model. In variational autoencoder, a constraint is added it forces the network to generate latent vectors that roughly follow a unit Gaussian distribution.
To generate new image, we sample a latent vector from the unit Gaussian and pass it into the decoder.
Loss
The loss includes:
* generative loss - i.e how accurately the network reconstruct the image and
* latent loss: how closely the latent variables match a unit Gaussian
The parameterization trick :
The latent loss is:
latent_loss = 0.5 tf.reduce_sum(tf.square(z_mean) + tf.square(z_stdev))
When we are calculating loss for the decoder network, we sample from the status and add the mean and use that as our latent vector.
samples = tf.random_normal([batch_size, ...n_z], 0.1, dtype=tf.float32)
sample_z = z_mean(z_stdev * samples)
In addition to allowing us to generate random latent variables, thus constraint also improves the generalization of our network.